


服务器密码遗忘是运维中常见的突发状况,需冷静采取应急措施。
在信息技术高速发展的今天,服务器作为企业数据存储、应用部署和业务运行的核心载体,其安全性与可访问性至关重要。即便是经验丰富的系统管理员,也可能遭遇因人员交接、密码策略复杂或记录疏失而导致的服务器密码遗忘问题。这不仅会直接导致关键业务中断,还可能引发数据访问延迟、安全响应滞后等一系列连锁风险。因此,一套清晰、高效且安全的紧急应对与恢复方案,不仅是技术储备,更是运维体系健壮性的体现。本文将系统阐述从紧急初步应对到深度恢复的全流程方案,并融入实际运维经验,旨在为技术人员提供一份可操作的行动指南。
当发现无法登录服务器时,首要原则是避免慌乱与非授权尝试。多次错误登录可能触发账户锁定或安全警报,甚至被入侵检测系统误判为攻击行为。第一步应立即启动事前预备的应急沟通流程,通知相关业务方潜在的服务延迟风险,并召集运维团队。同时,核查是否有其他备用认证方式,例如同一管理网络下的密钥对(SSH Key)登录、带外管理接口(如iDRAC、iLO、IPMI)或已建立的跳板机会话。这些预备通道是规避密码问题的第一道防线。
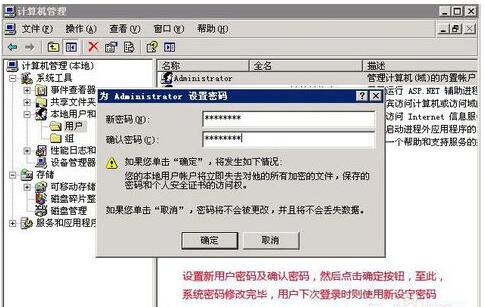
若常规替代路径无效,则需启动本地或物理恢复流程。对于物理服务器或具备本地访问权限的虚拟机,重启系统并介入引导加载程序是关键。以常见的Linux系统为例,在GRUB引导菜单界面,通过编辑内核启动参数,在行末添加 `init=/bin/bash` 或 `single` 等参数,可使系统直接跳入单用户模式或Bash shell。在此模式下,系统通常以root权限运行且无需密码,从而允许管理员直接使用 `passwd` 命令重置密码。对于Windows Server,则可使用安装介质进入恢复环境,通过替换或修改系统工具(如Utilman.exe)来启用无障碍功能,从而绕开登录界面调用命令行进行密码重置。此过程需注意:操作前应尽可能创建系统快照或备份,避免误操作导致数据丢失;操作后应立即更新所有关联的密码记录,并检查系统完整性。
在云服务器场景下,物理访问不可行,但主流云服务商(如AWS、Azure、阿里云、腾讯云)均提供了官方的密码重置机制。通常需要将云服务器实例关机,卸载其系统盘并作为数据盘挂载至另一台临时救援实例。在救援实例中,挂载该磁盘,针对不同系统修改其内部的密码哈希文件(如Linux的 `/etc/shadow` 或Windows的SAM数据库),完成后再将磁盘挂回原实例重启。云平台控制台通常提供向导式操作界面,但底层原理与此一致。此方法要求管理员对云平台操作和文件系统结构有清晰了解,且务必在操作前对原始磁盘制作镜像备份。
密码恢复后,事件并未结束,必须进行事后复盘与加固。应立即审计登录日志,确认在密码失效窗口期内有无异常访问尝试。此次事件应视为一次安全策略的压力测试。需审视现有密码管理流程:是否使用了集中化的特权访问管理(PAM)工具?密码是否定期轮换并有安全归档?是否启用了多因素认证(MFA)作为关键系统的补充?经验表明,单纯依赖记忆或分散的文本记录是高风险行为。建议引入密码管理器(如Bitwarden、1Password)团队版或专用密钥管理服务,并强制要求对所有服务器启用SSH密钥对认证,彻底降低对静态密码的依赖。
更深层次的反思应指向基础设施的韧性设计。是否实现了足够的权限分离和最小权限原则?是否配置了可靠的监控告警,能在服务异常时第一时间通知?是否建立了完善的文档和交接流程,确保知识不随人员流动而流失?一次密码遗忘事件,暴露的可能是整个运维体系的单点故障。因此,将其转化为改进的契机,推动自动化用户供应、零信任网络访问等更现代的安全架构落地,方能从根本上提升应对能力。
服务器密码遗忘虽属常见故障,但其处理过程综合考验着技术人员的知识储备、应急流程和系统化思维。从紧急介入恢复访问,到事后分析加固防御,每一个环节都需严谨对待。最有效的方案永远是预防优于补救。通过构建层次化的认证体系、集中化的密码管理和制度化的运维规范,可以将此类事件的发生概率和影响范围降至最低,确保核心业务服务的连续性与安全性。







